
Introduction
In today’s world of massive datasets and real-time applications, the ability to perform multiple tasks efficiently is not just an advantage—it’s a necessity. Terms like parallel processing and concurrent processing are often used interchangeably, but they describe fundamentally different approaches to achieving this goal. Understanding these concepts is crucial for developers, system architects, and anyone looking to optimize software performance and resource utilization.
This article will demystify these concepts, explore their key differences, and show how they work together in parallel concurrent processing to power modern computing.
What is Concurrency?
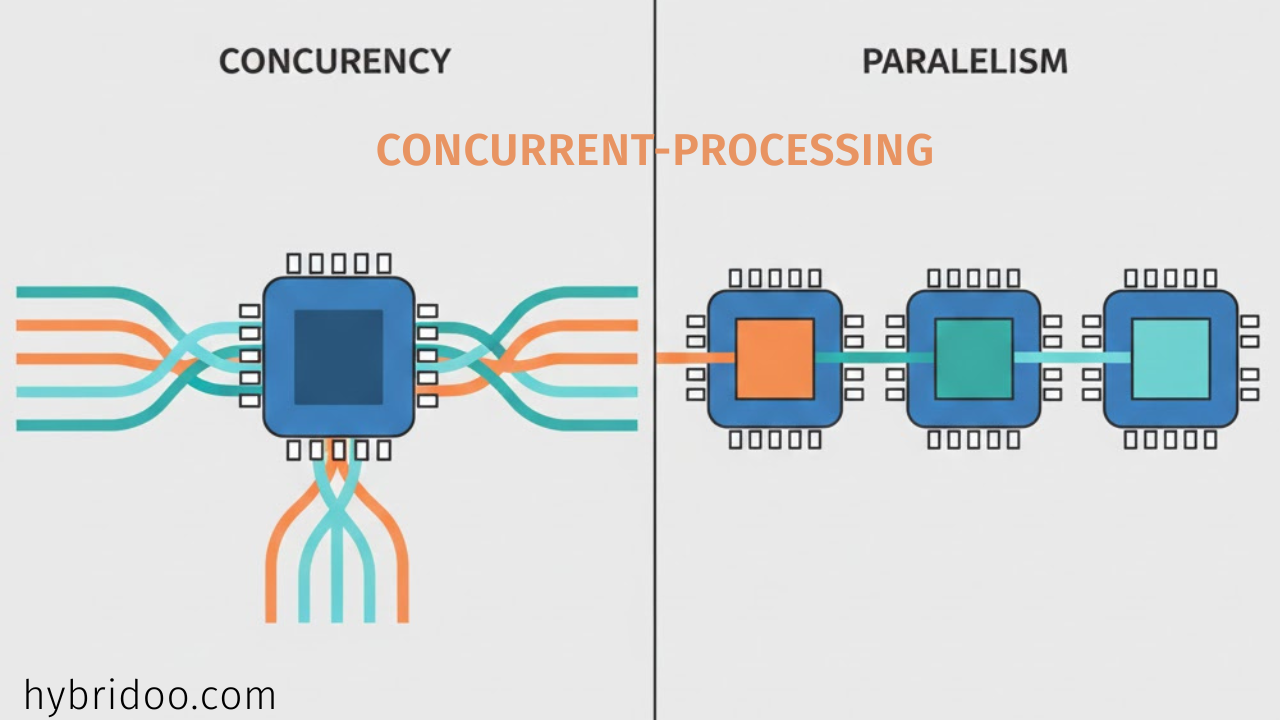
Concurrency is about dealing with multiple tasks at once. It creates the illusion of simultaneous execution by rapidly switching between tasks on a single processing unit. Think of a single cashier serving a line of customers by taking orders, processing payments, and bagging items in quick succession.
The core idea is to make progress on several tasks during overlapping time periods, which is particularly effective for I/O-bound operations (like waiting for network or disk responses). This is achieved through techniques like multithreading or asynchronous programming, where the CPU interleaves tasks so efficiently that to a user, they appear to happen at the same time.
What is Parallelism?
Parallelism refers to actually executing multiple tasks simultaneously on multiple processing units, such as separate CPU cores or different machines in a cluster. Using the cashier analogy, this would be a supermarket with multiple checkout lines operating at the same time. The primary goal of parallelism is to increase throughput and computational speed by leveraging multiple processors to do genuine simultaneous work.
Key Differences: Concurrency vs. Parallelism
While both concepts aim to improve efficiency, they operate on different principles. The table below summarizes the core distinctions:
| Aspect | Concurrency | Parallelism |
|---|---|---|
| Execution | Tasks appear to run simultaneously via rapid task switching (interleaving). | Tasks actually run at the same time across multiple processors. |
| System Requirement | Can be achieved on a single-core CPU through multitasking. | Requires a multi-core or multi-processor system. |
| Primary Goal | Optimizes responsiveness and resource utilization for I/O-bound tasks. | Maximizes throughput and speed for CPU-bound, divisible tasks. |
| Task Dependency | Tasks are often independent or can be efficiently interleaved. | Tasks are divided into smaller, independent sub-tasks that can be processed separately. |
| Control Flow | Non-deterministic; execution order may vary. | Deterministic; subtasks are processed in a more predictable manner. |
A common misconception is that concurrency always implies parallelism. In reality, all parallelism involves concurrency, but concurrency can exist without true parallelism. A multi-threaded application on a single-core CPU is concurrent but not parallel.
The Power of Parallel Concurrent Processing
A prime example is Oracle E-Business Suite’s PCP feature, which distributes background processing tasks (concurrent requests) across multiple application nodes in a cluster. This strategy delivers significant benefits:
-
High Performance & Throughput: Workloads are distributed across all available nodes, drastically reducing processing time for complex tasks.
-
Scalability: Processing capacity can be increased simply by adding more nodes to the environment.
-
Fault Tolerance & High Availability: If a node fails, its managed processes automatically migrate to a pre-assigned secondary node, ensuring continuous operation.
-
Efficient Resource Utilization: The workload is balanced across the entire hardware cluster, preventing any single server from becoming a bottleneck.
-
Single Point of Control: Administrators can manage all processes across all nodes from a unified interface, simplifying operations.
Practical Applications and Use Cases
The principles of concurrency and parallelism are applied across countless domains:
-
Web Servers & APIs: Concurrently handle thousands of user requests using frameworks like Node.js (async I/O) or multi-threaded server pools.
-
Data Processing & Big Data: Use parallel frameworks like Apache Spark to process petabytes of data by distributing computations across a cluster.
-
Scientific Computing & Simulations: Break down complex problems (e.g., climate modeling, molecular dynamics) into parallel tasks for supercomputers.
-
Artificial Intelligence & Machine Learning: Accelerate model training by using multiple GPUs to process different batches of data in parallel.
-
Desktop & Mobile Applications: Keep user interfaces responsive by running heavy computations in background threads (concurrency) or across available cores (parallelism).
Implementing Concurrency and Parallelism: A Code Example
Let’s look at a practical example in Python. Suppose we need to download content from hundreds of web pages.
A synchronous, sequential approach would process one page at a time, which is slow. A concurrent solution using threading can dramatically speed up this I/O-bound task by overlapping waiting times.
from concurrent.futures import ThreadPoolExecutor # Using concurrency (threading) for I/O-bound tasks with ThreadPoolExecutor(max_workers=16) as executor: executor.map(download_function, list_of_urls) # Faster download times
For a truly CPU-bound task like calculating the factorial of many large numbers, we would use parallelism with multiple processes to leverage all CPU cores.
from multiprocessing import Pool, cpu_count # Using parallelism (multiprocessing) for CPU-bound tasks with Pool(cpu_count()) as pool: pool.map(calculate_factorial, list_of_large_numbers)
Challenges and Best Practices
Harnessing these techniques comes with its own set of challenges:
-
Race Conditions: Occur when multiple threads/processes access and modify shared data without proper synchronization.
-
Deadlocks: Happen when two or more tasks are waiting for each other to release resources, causing a permanent stall.
-
Increased Complexity: Debugging and testing concurrent/parallel code is inherently more difficult than sequential code.
To mitigate these issues, follow these best practices:
-
Minimize Shared State: Design tasks to be as independent as possible.
-
Use Thread-Safe Data Structures: Employ queues, locks, and atomic operations from your language’s concurrency library.
-
Profile and Measure: Always benchmark to see if concurrency/parallelism actually improves performance for your specific use case.
-
Start Simple: Begin with a concurrent design, and introduce parallelism only when necessary, as it adds complexity.
Conclusion
Understanding the distinction between concurrency and parallelism is fundamental to building efficient, scalable software. Concurrency is about structure—managing multiple tasks at once—while parallelism is about execution—doing multiple things simultaneously. Together, as seen in parallel concurrent processing, they form the backbone of modern high-performance computing, from enterprise database systems to real-time web applications.
By choosing the right model for your task (I/O-bound vs. CPU-bound) and implementing it with careful attention to common pitfalls, you can unlock significant performance gains and build systems that make full use of today’s powerful, multi-core hardware.
Ready to dive deeper? Share your experiences or questions about implementing concurrent or parallel patterns in the comments below. For expert guidance on designing and optimizing high-performance, fault-tolerant systems, consider consulting with a specialist in distributed computing architectures.